Basics¶
Unitxt processes data in pipelines, by applying a modular sequence of operators. Each operator is of a specific ingredients type. Operators may be are defined and shared within the Unitxt Catalog. The operators compose larger unitxt Building Blocks.
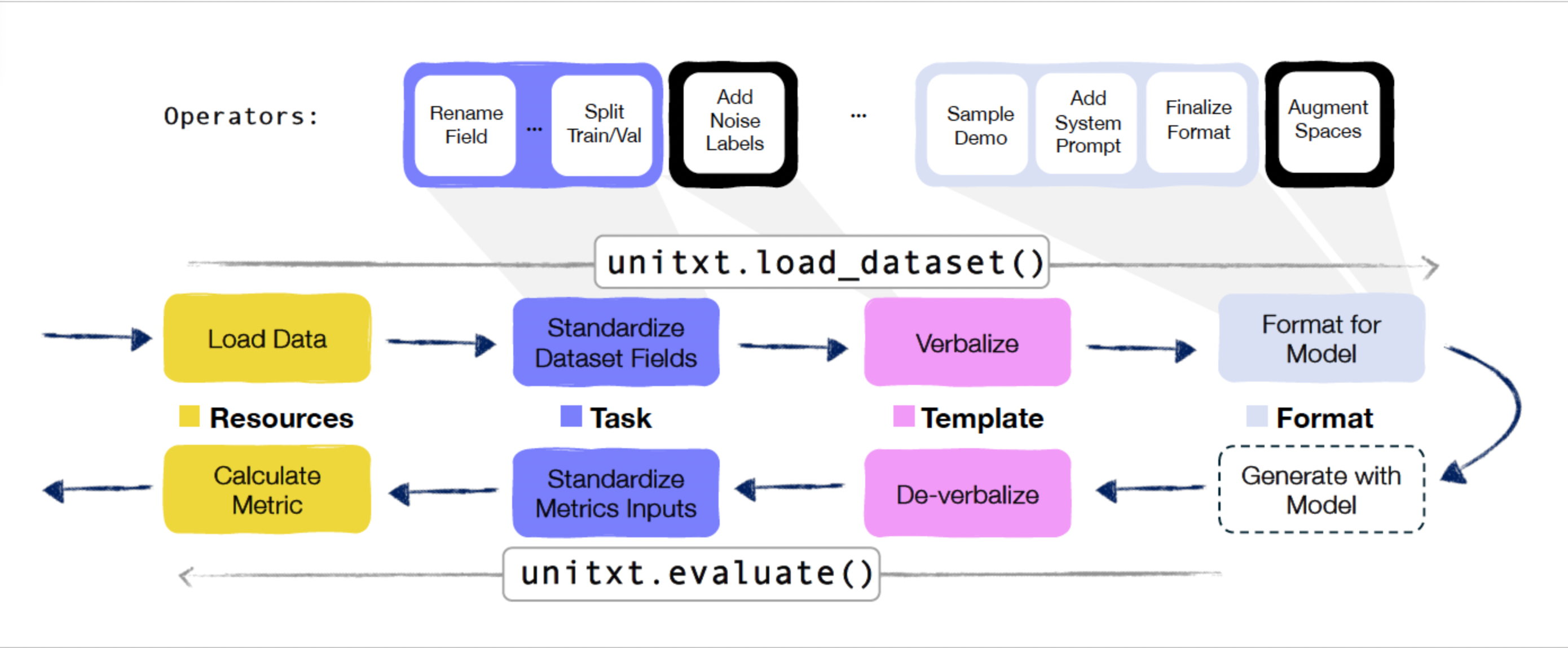
Here is a diagram of the unitxt flow depicting how the above components are used. The upper section illustrates the data-preparation pipeline (unitxt.load_dataset()), encompassing raw dataset loading, standardization according to the task interface, verbalization using templates, and application of formatting. The lower section showcases the evaluation pipeline (unitxt.evaluate()), involving de-verbalization operations and output standardization before performance evaluation with task-defined metrics. All components are described in detail below.
Building Blocks¶
When loading a dataset the Unitxt ingredients are retrieved based on a Data-Task Card and a Recipe.
Data-Task Card¶
Defines how raw data (inputs and targets) are standardized for a certain task. Typically, this includes data wrangling actions, e.g. renaming fields, filtering data instances, modifying values, train/test/val splitting etc. It also describes the resource from which the data is loaded.
The catalog contains predefined data-task cards for various datasets here.
Recipe¶
A Recipe holds a complete specification of a unitxt pipeline. This includes Resources, Task, Template, Format and Extensions.
The catalog contains predefined recipes here.
Ingredients¶
Resources¶
Unitxt implements several APIs for accessing external resources such as datasets and metrics:
Huggingface Hub
Local files
Cloud storage
Tasks¶
A Unitxt task follows the formal definition of an NLP task, such as multi-label classification, named entity extraction, abstractive summarization or translation. A task is defined by its standard interface – namely, input and output fields – and by its evaluation metrics. Given a dataset, its contents are standardized into the fields defined by an appropriate task by a Data-Task Card.
The catalog contains predefined tasks here.
As an example of a defined task, consider translation: it has three input fields (named text, source_language and target_language), one output field (named translation) and the metric normalized Sacrebleu.
Templates¶
A Unitxt Template defines the verbalizations to be applied to the inputs and targets, as well as the de-verbalization operations over the model predictions. For example, applying the template to “I like toast” verbalizes it into “classify the sentence: ``I like toast’’”:

In the other direction, template de-verbalization involves two steps. First, a general standardization of the output texts: taking only the first non-empty line of a model’s predictions, lowercasing, stripping whitespaces, etc. The second step standardizes the output to the specific task at-hand. For example, in Sentence Similarity, a prediction may be a quantized float number outputted as a string (e.g ``2.43’’), or a verbally expressed numeric expression (e.g ``two and a half’’). This depends on the verbalization defined by the template and the in-context demonstrations it constructs. Both types of outputs should be standardized before evaluation begins – e.g. to a float for sentence similarity. Having the de-verbalization steps defined within the template enables templates reuse across different models and datasets.
The templates, datasets and tasks in Unitxt are not exclusively tied. Each task can harness multiple templates and a template can be used for different datasets.
The catalog contains predefined templates here.
Formats¶
A Unitxt Format defines a set of extra formatting requirements, unrelated to the underlying data or task, including those pertaining to system prompts, special tokens or user/agent prefixes, and in-context demonstrations.
Continuing the example from the above figure, the Unitxt format receives the text produced by the template “classify the sentence: ``I like toast’’”, and adds the system prompt “<SYS>You are a helpful agent</SYS>”, the Instruction-User-Agent schema cues, and the two presented demonstrations.
The catalog contains predefined formats here.
Extensions¶
Unitxt supports Extensions such as “input-augmentation” (for example, adding random whitespace, introducing spelling mistakes, or replacing words with their synonyms) or label-noising (replaces the labels in the demonstrations randomly from a list of options). Such extensions can be added anywhere in the data-preparation pipeline between any two operators, depending on the desired logic (see the unitxt flow diagram).
Unitxt supports the addition of custom extensions to the Unitxt Catalog. Each extension is an independent unit, reusable across different datasets and tasks, templates and formats.
Pipelines¶
Data Preparation Pipeline¶
The data preparation pipeline begins with standardizing the raw data into the task interface, as defined in the data-task card. The examples are then verbalized by the template, and the format operator applies system prompts, special tokens and in-context learning examples. To maintain compatibility, the output of this pipeline is a HuggingFace dataset, that can be saved or pushed to the hub.
Evaluation Pipeline¶
The evaluation pipeline is responsible for producing a list of evaluation scores that reflect model performance. It includes a de-verbalization of the model outputs (as defined in the template), and a computation of performance by the metrics defined in the task.
The standardization of the task interface, namely, having fixed names and types for its input and output fields, allows the use of any metric that accept such fields as input. In addition to the computed evaluation scores, Unitxtx metrics supports a built in mechanism for confidence interval reporting, using statistical bootstrap.
The Unitxt Catalog¶
All Unitxt artifacts – recipes, data-task cards, templates, pre-processing operators, formats and metrics – are stored in the Unitxt Catalog.
In addition to the open-source catalog, that can be found in the documentation, users can choose to define a private catalog. This enables teams and organizations to harness the open Unitxt Catalog while upholding organizational requirements for additional proprietary artifacts.